The goal of this document is to provide a set of guidelines and tips helping the publication and deployment of XML resources for the GNOME project. However it is not tied to GNOME and might be helpful more generally. I welcome feedback on this document.
The intended audience is the software developers who started using XML for some of the resources of their project, as a storage format, for data exchange, checking or transformations. There have been an increasing number of new XML formats defined, but not all steps have been taken, possibly because of lack of documentation, to truly gain all the benefits of the use of XML. These guidelines hope to improve the matter and provide a better overview of the overall XML processing and associated steps needed to deploy it successfully:
Table of contents:
This part intends to focus on the format itself of XML. It may arrive a bit too late since the structure of the document may already be cast in existing and deployed code. Still, here are a few rules which might be helpful when designing a new XML vocabulary or making the revision of an existing format:
This may sounds a bit simplistic, but before designing your own format, try to lookup existing XML vocabularies on similar data. Ideally this allows you to reuse them, in which case a lot of the existing tools like DTD, schemas and stylesheets may already be available. If you are looking at a documentation format, DocBook should handle your needs. If reuse is not possible because some semantic or use case aspects are too different this will be helpful avoiding design errors like targeting the vocabulary to the wrong abstraction level. In this format design phase try to be synthetic and be sure to express the real content of your data and use the XML structure to express the semantic and context of those data.
Building a DTD (Document Type Definition) or a Schema describing the structure allowed by instances is the core of the design process of the vocabulary. Here are a few tips:
<welcome> <msg xml:lang="en">hello</msg> <msg xml:lang="fr">bonjour</msg> </welcome>
As part of the design, make sure the structure you define will be usable for future extension that you may not consider for the current version. There are two parts to this:
version="1.0" on the root document of the instance is
sufficient.While defining you vocabulary, try to think in term of other usage of your data, for example how using XSLT stylesheets could be used to make an HTML view of your data, or to convert it into a different format. Checking XML Schemas and looking at defining an XML Schema with a more complete validation and datatyping of your data structures is important, this helps avoiding some mistakes in the design phase.
If you expect your XML vocabulary to be used or recognized outside of your application (for example binding a specific processing from a graphic shell like Nautilus to an instance of your data) then you should really define an XML namespace for your vocabulary. A namespace name is an URL (absolute URI more precisely). It is generally recommended to anchor it as an HTTP resource to a server associated with the software project. See the next section about this. In practice this will mean that XML parsers will not handle your element names as-is but as a couple based on the namespace name and the element name. This allows it to recognize and disambiguate processing. Unicity of the namespace name can be for the most part guaranteed by the use of the DNS registry. Namespace can also be used to carry versioning information like:
"http://www.gnome.org/project/projectname/1.0/"
An easy way to use them is to make them the default namespace on the root element of the XML instance like:
<structure xmlns="http://www.gnome.org/project/projectname/1.0/"> <data> ... </data> </structure>
In that document, structure and all descendant elements like data are in the given namespace.
As seen in the previous namespace section, while XML processing is not tied to the Web there is a natural synergy between both. XML was designed to be available on the Web, and keeping the infrastructure that way helps deploying the XML resources. The core of this issue is the notion of "Canonical URL" of an XML resource. The resource can be an XML document, a DTD, a stylesheet, a schema, or even non-XML data associated with an XML resource, the canonical URL is the URL where the "master" copy of that resource is expected to be present on the Web. Usually when processing XML a copy of the resource will be present on the local disk, maybe in /usr/share/xml or /usr/share/sgml maybe in /opt or even on C:\projectname\ (horror !). The key point is that the way to name that resource should be independent of the actual place where it resides on disk if it is available, and the fact that the processing will still work if there is no local copy (and that the machine where the processing is connected to the Internet).
What this really means is that one should never use the local name of a resource to reference it but always use the canonical URL. For example in a DocBook instance the following should not be used:
<!DOCTYPE article PUBLIC "-//OASIS//DTD DocBook XML V4.2//EN"
"/usr/share/xml/docbook/4.2/docbookx.dtd">
But always reference the canonical URL for the DTD:
<!DOCTYPE article PUBLIC "-//OASIS//DTD DocBook XML V4.2//EN"
"http://www.oasis-open.org/docbook/xml/4.2/docbookx.dtd">
Similarly, the document instance may reference the XSLT stylesheets needed to process it to generate HTML, and the canonical URL should be used:
<?xml-stylesheet href="http://docbook.sourceforge.net/release/xsl/current/html/docbook.xsl" type="text/xsl"?>
Defining the canonical URL for the resources needed should obey a few simple rules similar to those used to design namespace names:
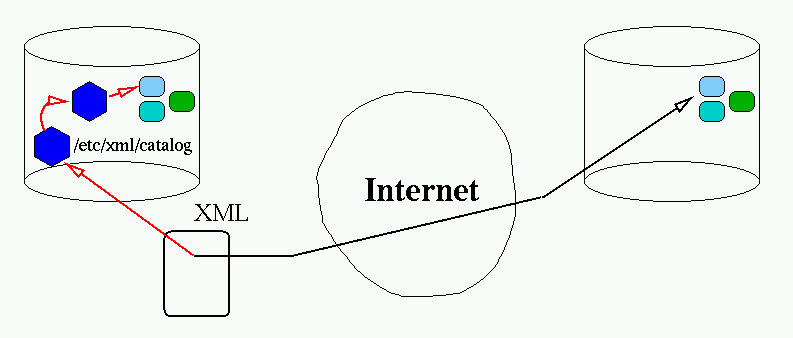
The catalogs are the technical mechanism which allow the XML processing
tools to use a local copy of the resources if it is available even if the
instance document references the canonical URL. XML Catalogs are
anchored in the root catalog (usually /etc/xml/catalog or
defined by the user). They are a tree of XML documents defining the mappings
between the canonical naming space and the local installed ones, this can be
seen as a static cache structure.
When the XML processor is asked to process a resource it will
automatically test for a locally available version in the catalog, starting
from the root catalog, and possibly fetching sub-catalog resources until it
finds that the catalog has that resource or not. If not the default
processing of fetching the resource from the Web is done, allowing in most
case to recover from a catalog miss. The key point is that the document
instances are totally independent of the availability of a catalog or from
the actual place where the local resource they reference may be installed.
This greatly improves the management of the documents in the long run, making
them independent of the platform or toolchain used to process them. The
figure below tries to express that mechanism:
Usually catalogs for a project are setup as a 2 level hierarchical cache, the root catalog containing only "delegates" indicating a separate subcatalog dedicated to the project. The goal is to keep the root catalog clean and simplify the maintenance of the catalog by using separate catalogs per project. For example when creating a catalog for the XHTML1 DTDs, only 3 items are added to the root catalog:
<delegatePublic publicIdStartString="-//W3C//DTD XHTML 1.0"
catalog="file:///usr/share/sgml/xhtml1/xmlcatalog"/>
<delegateSystem systemIdStartString="http://www.w3.org/TR/xhtml1/DTD"
catalog="file:///usr/share/sgml/xhtml1/xmlcatalog"/>
<delegateURI uriStartString="http://www.w3.org/TR/xhtml1/DTD"
catalog="file:///usr/share/sgml/xhtml1/xmlcatalog"/>
They are all "delegates" meaning that if the catalog system is asked to
resolve a reference corresponding to them, it has to lookup a sub catalog.
Here the subcatalog was installed as
/usr/share/sgml/xhtml1/xmlcatalog in the local tree. That
decision is left to the sysadmin or the packager for that system and may
obey different rules, but the actual place on the filesystem (or on a
resource cache on the local network) will not influence the processing as
long as it is available. The first rule indicate that if the reference uses a
PUBLIC identifier beginning with the
"-//W3C//DTD XHTML 1.0"
substring, then the catalog lookup should be limited to the specific given
lookup catalog. Similarly the second and third entries indicate those
delegation rules for SYSTEM, DOCTYPE or normal URI references when the URL
starts with the "http://www.w3.org/TR/xhtml1/DTD" substring
which indicates the location on the W3C server where the XHTML1 resources are
stored. Those are the beginning of all Canonical URLs for XHTML1 resources.
Those three rules are sufficient in practice to capture all references to XHTML1
resources and direct the processing tools to the right subcatalog.
Here is the complete subcatalog used for XHTML1:
<?xml version="1.0"?>
<!DOCTYPE catalog PUBLIC "-//OASIS//DTD Entity Resolution XML Catalog V1.0//EN"
"http://www.oasis-open.org/committees/entity/release/1.0/catalog.dtd">
<catalog xmlns="urn:oasis:names:tc:entity:xmlns:xml:catalog">
<public publicId="-//W3C//DTD XHTML 1.0 Strict//EN"
uri="xhtml1-20020801/DTD/xhtml1-strict.dtd"/>
<public publicId="-//W3C//DTD XHTML 1.0 Transitional//EN"
uri="xhtml1-20020801/DTD/xhtml1-transitional.dtd"/>
<public publicId="-//W3C//DTD XHTML 1.0 Frameset//EN"
uri="xhtml1-20020801/DTD/xhtml1-frameset.dtd"/>
<rewriteSystem systemIdStartString="http://www.w3.org/TR/xhtml1/DTD"
rewritePrefix="xhtml1-20020801/DTD"/>
<rewriteURI uriStartString="http://www.w3.org/TR/xhtml1/DTD"
rewritePrefix="xhtml1-20020801/DTD"/>
</catalog>
There are a few things to notice:
/usr/share/sgml/xhtml1/xmlcatalog/xhtml1-20020801/DTD/xhtml1-strict.dtdThose 5 rules are sufficient to cover all references to the resources held at the Canonical URL for the XHTML1 DTDs.
Creating and removing catalogs should be handled as part of the process of (un)installing the local copy of the resources. The catalog files being XML resources should be processed with XML based tools to avoid problems with the generated files, the xmlcatalog command coming with libxml2 allows you to create catalogs, and add or remove rules at that time. Here is a complete example coming from the RPM for the XHTML1 DTDs post install script. While this example is platform and packaging specific, this can be useful as a an example in other contexts:
%post
CATALOG=/usr/share/sgml/xhtml1/xmlcatalog
#
# Register it in the super catalog with the appropriate delegates
#
ROOTCATALOG=/etc/xml/catalog
if [ ! -r $ROOTCATALOG ]
then
/usr/bin/xmlcatalog --noout --create $ROOTCATALOG
fi
if [ -w $ROOTCATALOG ]
then
/usr/bin/xmlcatalog --noout --add "delegatePublic" \
"-//W3C//DTD XHTML 1.0" \
"file://$CATALOG" $ROOTCATALOG
/usr/bin/xmlcatalog --noout --add "delegateSystem" \
"http://www.w3.org/TR/xhtml1/DTD" \
"file://$CATALOG" $ROOTCATALOG
/usr/bin/xmlcatalog --noout --add "delegateURI" \
"http://www.w3.org/TR/xhtml1/DTD" \
"file://$CATALOG" $ROOTCATALOG
fi
The XHTML1 subcatalog is not created on-the-fly in that case, it is installed as part of the files of the packages. So the only work needed is to make sure the root catalog exists and register the delegate rules.
Similarly, the script for the post-uninstall just remove the rules from the catalog:
%postun
#
# On removal, unregister the xmlcatalog from the supercatalog
#
if [ "$1" = 0 ]; then
CATALOG=/usr/share/sgml/xhtml1/xmlcatalog
ROOTCATALOG=/etc/xml/catalog
if [ -w $ROOTCATALOG ]
then
/usr/bin/xmlcatalog --noout --del \
"-//W3C//DTD XHTML 1.0" $ROOTCATALOG
/usr/bin/xmlcatalog --noout --del \
"http://www.w3.org/TR/xhtml1/DTD" $ROOTCATALOG
/usr/bin/xmlcatalog --noout --del \
"http://www.w3.org/TR/xhtml1/DTD" $ROOTCATALOG
fi
fi
Note the test against $1, this is needed to not remove the delegate rules in case of upgrade of the package.
Following the set of guidelines and tips provided in this document should help deploy the XML resources in the GNOME framework without much pain and ensure a smooth evolution of the resource and instances.
$Id: guidelines.html,v 1.6 2004/12/26 21:01:48 veillard Exp $