The Abstract of the current working draft says:
This specification defines the XML Pointer Language (XPointer),
the language to be used as a fragment identifier for any URI-reference
that locates a resource of Internet media type text/xml or application/xml.
And RFC 2396 states:
The semantics of a fragment identifier is a property of the data
resulting from a retrieval action, regardless of the type of URI used
in the reference. Therefore, the format and interpretation of fragment
identifiers is dependent on the media type [RFC2046] of the retrieval
result.
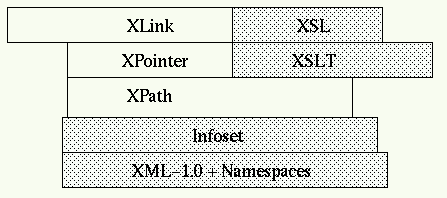
XPath describes the syntax and associated processing to select groups of nodes and attributes within an XML document tree.
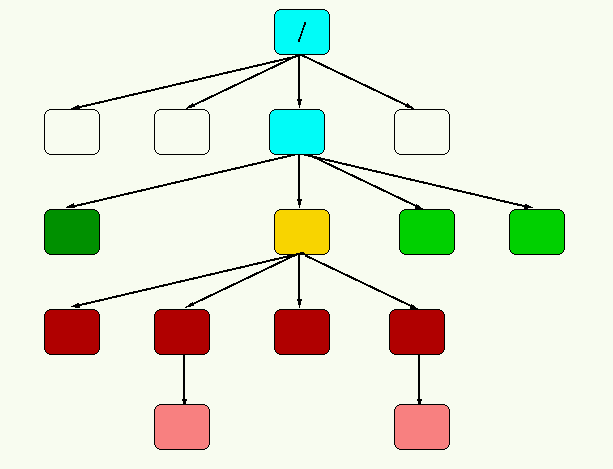
child::para selects the para element children
child::* selects the element children
/descendant::para all the para elements of the document
/doc/chapter[5]/section[2] the second section of the fifth chapter of the doc elements under the document root
/descendant::p[position()=last()] the last p in document order
//note[@type="warning"] all note elements that has a type attribute with value warning
XPointer
#Intro
#xpointer(id(intro))
Node concept is extended to nodes, points and ranges
and associated cast functions
string-range() function to address within (nodes) content
here() and origin() to refer to
the XPointer expression location and hypertext traversal
start-point() and end-point() to
address beginning and ending of locations.
unique() function to detect absence or multiple return
values.
#xpointer(//*[local-name()='y' and namespace-uri()='http://www.foo.com/bar']) locates all the y elements from the namespace whose URI is
http://www.foo.com/bar
xpointer(id("sec2.1")//p[2] to id("sec2.2")//p[last()])
selects the range from the second p child of sec2.1 to the end of the last
p in sec2.2
string-range(//title,"XPointer") returns the set of ranges
containing "XPointer" strings when they occur within title elements